同じ 「衛星の数は?」 という質問をChatGPTに尋ねてみましょう。

ご覧の通り、この情報は 最後の更新時点でのみ有効 だと言及しています. この質問に正確に答えるためにモデルを再訓練する必要がありますが、それは常に実現可能ではありません。さらに、LLMを「最新の状態に保つ」ことは非常に困難で経済的ではありません。
そこで検索拡張生成 (RAG)が登場します。これはLLMの幻覚と古い訓練データの両方の問題に対処するための戦略です。LLMをこのアーキテクチャと組み合わせることで、追加の訓練に時間とお金をかけることなく、その能力を向上させることができます。
大規模言語モデルの仕組みは、ユーザーが衛星についての質問(プロンプトとも呼ばれる)をすると、LLMは訓練時のパラメータから知っている「木星」と自信を持って答えるというものです。LLMはこの応答生成を行う際にかなり自信を持っていますが、おそらく間違っているでしょう。
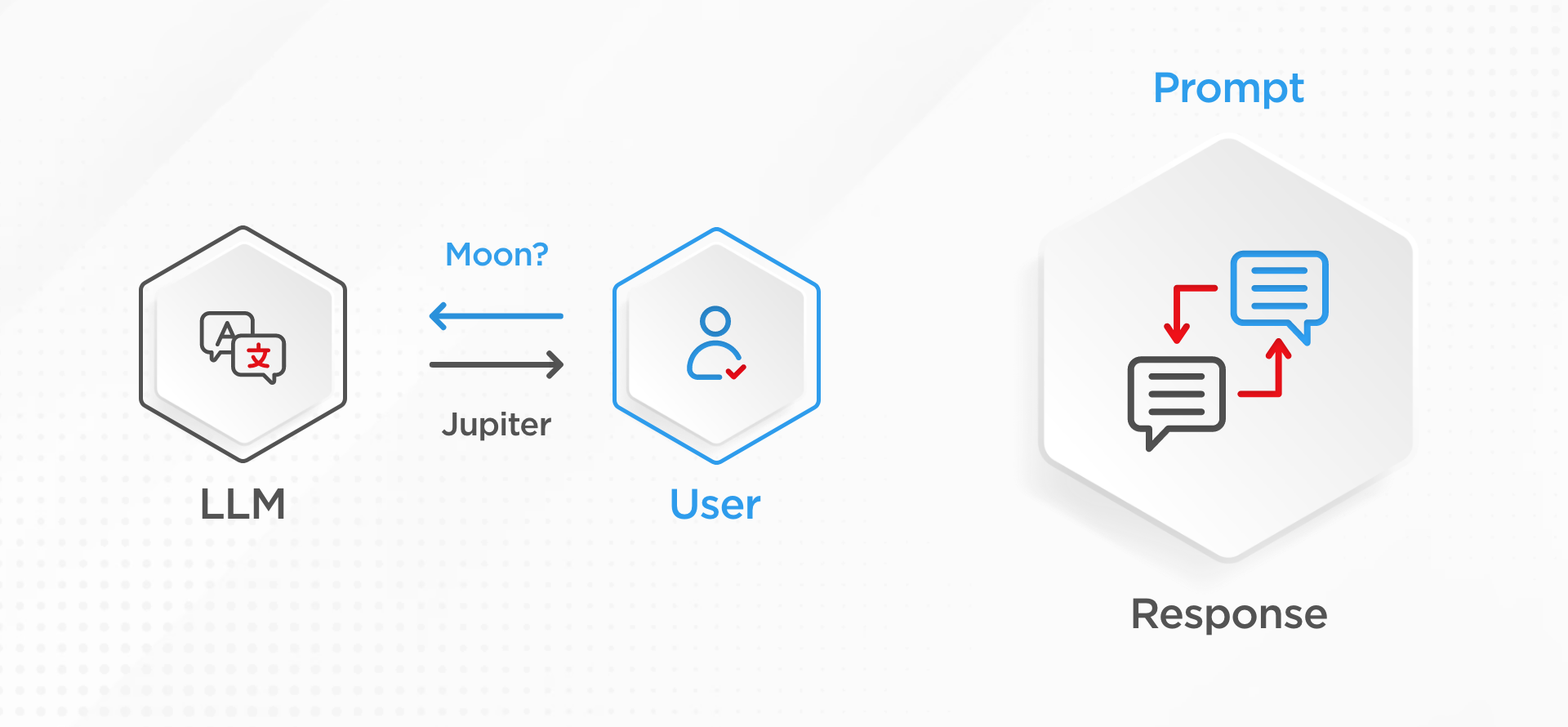
しかし、この生成プロセスに検索拡張を追加すると、LLMが知っていることだけに頼るのではなく、コンテンツストアデータを追加します。このコンテンツストアデータは、文書のコレクション、内部または外部のデータベース、あるいはオープンなインターネットなど、何でも構いません。これにより、LLMは今やプロンプトとともに提供される指示セットを持ち、以下のように言います:
- まず、このコンテンツストアで関連する文脈的に適切な情報を探し、それをユーザーの質問と組み合わせてください。
- そして、その後にのみ、なぜその応答になったのかの証拠とともに回答を生成してください。

